Introduction
Machine learning (ML) is revolutionizing the field of data science, enabling computers to learn from and make decisions based on data. Whether you’re a data enthusiast or an aspiring data scientist, understanding the basics of machine learning algorithms is essential. This guide will walk you through some of the most fundamental ML algorithms used in data science today.
What is Machine Learning?
Machine learning is a subset of artificial intelligence (AI) that focuses on building systems that can learn from data, identify patterns, and make decisions with minimal human intervention. Unlike traditional programming, where explicit instructions are given to achieve specific tasks, ML algorithms learn from the data to perform tasks. Over the years, ML has evolved from basic linear models to complex neural networks capable of surpassing human performance in various tasks.
Types of Machine Learning
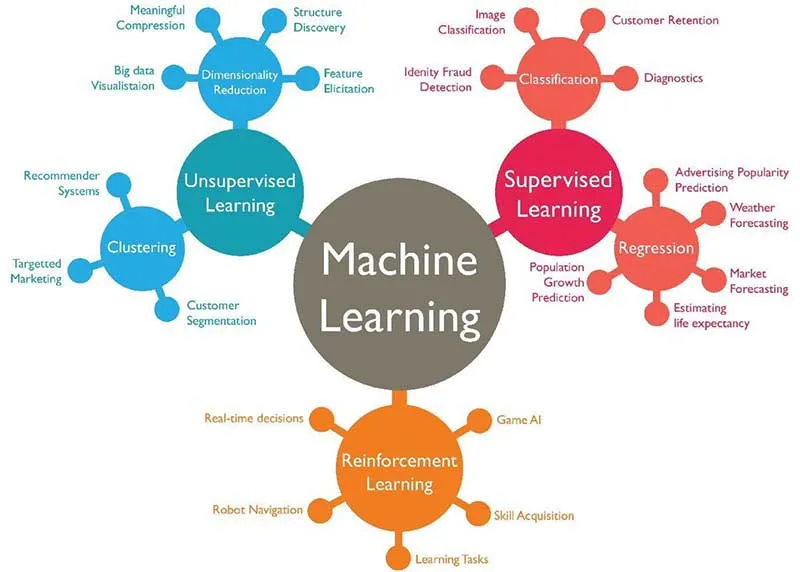
There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.
Supervised Learning: Involves training a model on labeled data. This means the data comes with input-output pairs, and the algorithm learns to map inputs to the correct outputs.
Unsupervised Learning: Deals with unlabeled data. The algorithm tries to learn the patterns and the structure from the data without any specific output values.
Reinforcement Learning: The algorithm learns by interacting with an environment and receiving feedback in the form of rewards or penalties..
Key Machine Learning Algorithms
Understanding the different algorithms is crucial for selecting the right one for your data science projects.
Linear Regression
Linear regression is a simple algorithm used for predicting a continuous variable. It assumes a linear relationship between the input variables (features) and the output variable. For example, predicting house prices based on features like square footage and number of bedrooms.
Logistic Regression
Despite its name, logistic regression is used for classification problems. It predicts the probability of a binary outcome using a logistic function. It’s widely used in scenarios like spam detection and medical diagnosis (e.g., predicting whether a patient has a certain disease).
Decision Trees
Decision trees are versatile algorithms used for both classification and regression tasks. They work by splitting the data into subsets based on the value of input features. Each node represents a feature, each branch represents a decision, and each leaf represents an outcome. Decision trees are intuitive and easy to visualize, making them popular in various applications.
Support Vector Machines (SVM)
SVMs are used for classification tasks. They work by finding the hyperplane that best separates the data into different classes. SVMs are effective in high-dimensional spaces and are used in applications such as image classification and bioinformatics.
K-Nearest Neighbors (KNN)
KNN is a simple, non-parametric algorithm used for both classification and regression. It classifies data points based on the majority class among the k-nearest neighbors. KNN is easy to implement and understand, and it’s often used in recommendation systems and pattern recognition.
Neural Networks
Neural networks are the foundation of deep learning. They consist of interconnected nodes (neurons) that process data in layers, enabling the model to learn complex patterns. Neural networks are used in a variety of applications, including image and speech recognition, natural language processing, and autonomous driving.
Random Forest
Random forest is an ensemble method that combines multiple decision trees to improve the model’s accuracy and reduce overfitting. It is used for both classification and regression tasks. Random forests are robust and perform well on a variety of problems, including feature selection and anomaly detection.
Gradient Boosting Machines (GBM)
GBMs are powerful ensemble algorithms that build models sequentially, with each new model correcting the errors of the previous ones. They are widely used in competitions and real-world applications for their high predictive performance. Examples include XGBoost and LightGBM.
Choosing the Right Algorithm
Choosing the right algorithm is a crucial step in any machine learning project. Here are some typical problems and the common algorithms used to solve them:
Classification Problems
- Spam Detection: Logistic Regression, Decision Trees, Random Forest, SVM
- Image Recognition: Convolutional Neural Networks (CNN), SVM
- Medical Diagnosis: Logistic Regression, Decision Trees, Random Forest
Regression Problems
- House Price Prediction: Linear Regression, Decision Trees, Random Forest, Gradient Boosting Machines
- Stock Price Prediction: Linear Regression, Support Vector Regression (SVR), Recurrent Neural Networks (RNN)
Clustering Problems
- Customer Segmentation: K-Means Clustering, Hierarchical Clustering
- Anomaly Detection: DBSCAN, Isolation Forest
Reinforcement Learning Problems
- Game Playing: Q-Learning, Deep Q-Networks (DQN)
- Robotics: Policy Gradient Methods, Q-Learning
Natural Language Processing (NLP) Problems
- Sentiment Analysis: Naive Bayes, Recurrent Neural Networks (RNN), Transformers
- Language Translation: Long Short-Term Memory (LSTM) Networks, Transformers
Considerations for Choosing an Algorithm
- Type of Problem: Determine whether the problem is a classification, regression, clustering, or reinforcement learning task.
- Size and Nature of Data: Large datasets with high dimensionality may require different algorithms (e.g., SVM or Neural Networks) compared to smaller, simpler datasets.
- Computational Resources: Neural networks and ensemble methods like random forests can be computationally intensive. Consider your available resources.
- Model Interpretability: Some algorithms like decision trees are easier to interpret, while others like neural networks are often seen as “black boxes.”
- Accuracy and Performance: Experiment with different algorithms and use techniques like cross-validation to find the best performing model.
Resources to Learn More
To delve deeper into machine learning, consider these resources: