As organizations increasingly rely on data-driven decision-making, the expectations placed on analytics and engineering teams continue to grow. Delivering clean, reliable, and production-ready data workflows is no longer a luxury, but a requirement. This is where DataOps comes into play, as it brings DevOps thinking into the data world: reproducibility, automation, rapid iteration, quality assurance, and collaboration. Databricks, with its unified compute platform becomes significantly more powerful when it’s paired with a solid DataOps foundation. This article walks through a modern, lightweight but effective DataOps stack for Databricks, built on the following components.
- Databricks Asset Bundles (DABs)
- GitHub Actions
- UV for environment anddependency management
- Python wheels as deployable, versioned application artifacts
- Pre-commit for quality assurance
- Local PySpark runs to accelerate development and reduce costs
- Sound project structure to encourage reuse, clarity, and maintainability
Why DataOps Matters in Databricks
- Inconsistent coding style
- Fragmented business logic buried in notebooks
- Manual UI-based configuration changes
- Fragile deployment steps
- Difficult onboarding
- Workflows that behave differently for every developer
- Shorter development cycles
- Fewer production issues
- Easier audits and governance
- More efficient collaboration
- Improved maintainability
Key Components of a Modern Databricks DataOps Framework
1. Databrick Asset Bundles (DABs)
DABs provide a hermetic, versioned packaging layer for your Databricks code. The entire project with its jobs, workflows, notebooks, Python packages, configurations is captured in an immutable bundle definition.This ensures environment parity between development, staging, and production. Deployments become fully reproducible, with no drift and no hidden workspace state.
Challenge: manual UI config, hard-coded values, environment drift, silos due to notebooks & local config
Value: source-control, infrastructure-as-code (IaC), consistency, dynamic environment-handling thanks to variables
2. GitHub Actions (CI/CD)
GitHub Actions provides deterministic CI/CD orchestration. It executes the same steps (building the wheel, running tests, enforcing pre-commit, validating and deploying the bundle) withoutmanual intervention every time, thus there are no drifts.
Challenge: manual CI steps, environment drift, inconsistency in developer collaboration and CI steps
Value: reliable and reproducible releases with auditability, proper secret management, automated CI, tailored workflow trigger strategy
3. UV – blazing fast Python env & dependency management
UV creates hermetic, immutable, Docker-like Python environments. Once locked, the environment cannot drift, so every developer and every CI run gets the same dependencies, bit-for-bit.
Challenge: “works on my machine” situations, slow builds, inconsistent environments
Value: container-like, reproducible, 10-100x faster package install, easy dependency management via source-controlled project file
4. Python Wheel Packaging
A Python wheel acts like a packaged, immutable build artifact, similar to a Docker image. Packaging your application logic as a Python wheel enforces real software-engineering structure inside Databricks workflows. Instead of scattering logic across notebooks, the core transformations, utilities, and business rules live in clean, versioned Python modules. This makes logic reusable, testable, and CI-friendly.
Challenge: hidden logic buried in notebooks, duplicated transformations, no clear versioning
Value: modular, testable, versioned code that integrates seamlessly with CI/CD and DABs
5. Pre-commit
In short, pre-commit keeps code clean at the source and guarantees consistency across the team and the pipeline. Locally it prevents low-quality code, security risks, and formatting issues from ever being committed. In CI it provides a consistent, enforceable quality baseline, ensuring all contributions meet the same standards.
Challenge: inconsistent coding styles, silent low-level bugs, noisy code reviews
Value: automatically enforced quality; clean, predictable codebase across the whole team
6. Local PySpark Execution
Local PySpark lets developers test transformations on their own machine, avoiding slow cluster roundtrips. This dramatically shortens the feedback loop, making debugging, prototyping, and unit testing far more efficient, without consuming Databricks compute, so such configuration can be a valuable addition.
Challenge: long debug cycles, cluster dependency, costly iteration
Value: fast, inexpensive experimentation with a tight feedback loop and better debugging tools
7. Sound Project Structure & Reusable Components
A well-designed project structure with clear modules, shared utilities, typed configs, and documentation creates a maintainable foundation for DataOps. It reduces duplication, improves clarity, and makes it easy for new developers to understand where logic lives and how components interact.
Challenge: tangled repositories, duplicated code, unclear boundaries and responsibilities
Value: scalable, intuitive engineering environment where onboarding is smooth and collaboration is effortless

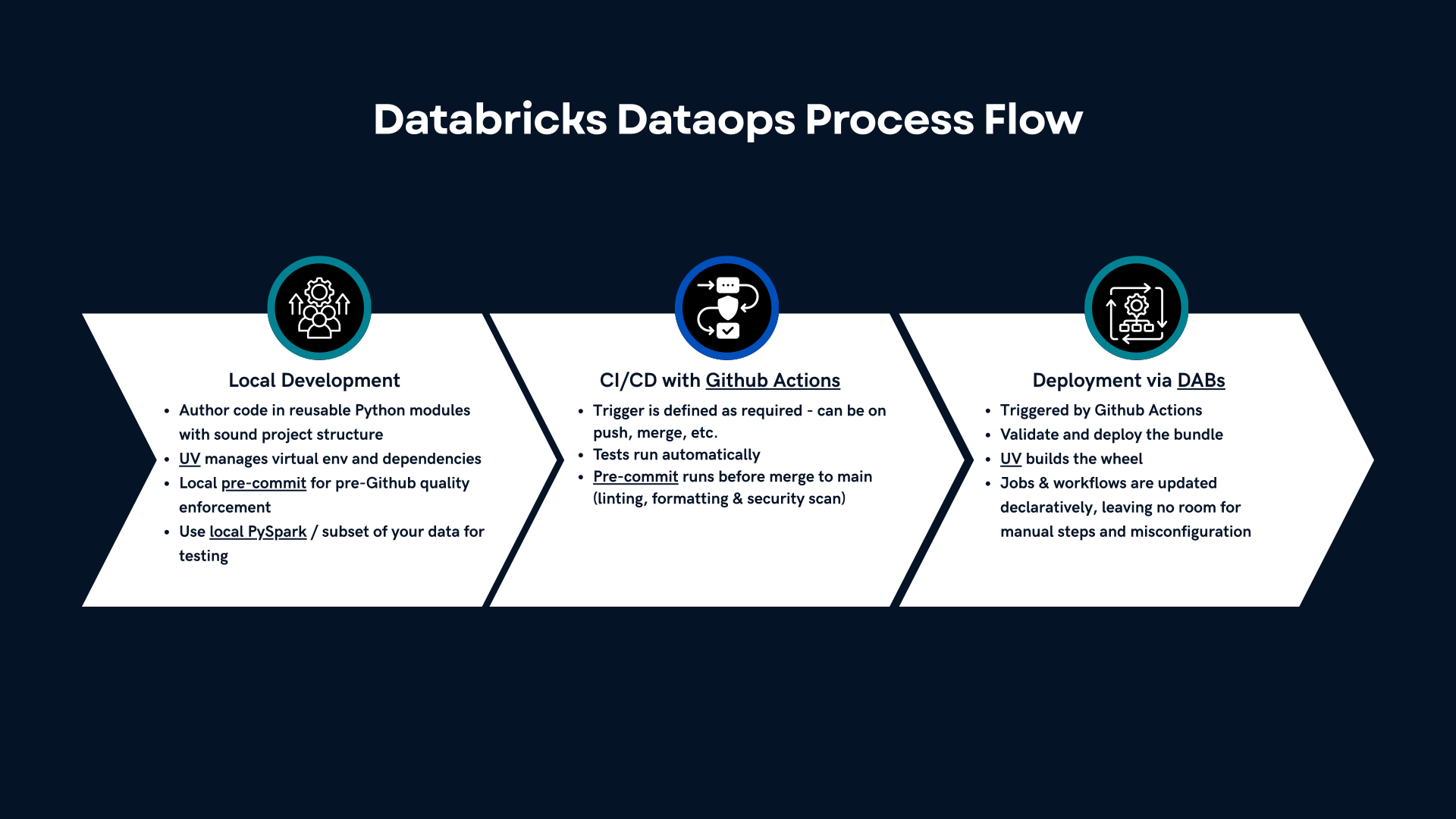
A Typical End-to-End Development Flow
Here’s how these tools come together into a coherent, professional workflow:
- Develop locally
- Write logic in Python modules
- UV manages your virtual env and dependencies
- Test transformations using local PySpark – this is optional, but it’s always recommended to use small subset of your data
- pre-commit enforces quality before committing anything
- Push to GitHub → CI kicks in
- Tests run automatically
- Linting, formatting, and security scans execute
- UV builds the wheel
- DABs validates and deploys the bundle
- Automated deployment to Databricks
- Jobs and workflows are updated declaratively
- No manual steps, no accidental misconfiguration
This is how this compact and modern data engineering configuration works.
Conclusion — A DataOps Foundation That Scales
A well-designed DataOps workflow is no longer a luxury in Databricks projects—it’s the foundation that ensures quality, reliability, and long-term scalability. The approach described here strikes the right balance: lightweight enough for small teams yet robust enough for enterprise-level delivery. By combining Databricks Asset Bundles, GitHub Actions, UV, Python wheels, pre-commit hooks, and local PySpark development, you shift Databricks from an ad-hoc notebook environment into a structured, automated, production-ready engineering platform.
This setup delivers a workflow that is:
- Clean – consistent formatting, typed code, reproducible builds
- Automated – CI/CD validates quality before anything deploys
- Scalable – modular architecture and wheels enable reuse
- Predictable – deterministic environments and controlled releases
- Collaborative – Git-driven development without notebook conflicts
- Future-proof – aligned with modern software engineering standards
What This Means in Practice
For engineers:
- Faster development loops
- Far fewer errors
- Clearer architecture
- Easy to reuse modules across projects
- High confidence deployments
For teams & leaders:
- Predictable delivery timelines
- Better compliance and governance
- Cheaper development and maintenance
- Improved onboarding speed
- Collaboration without stepping on each other’s toes
For clients:
- A professional-grade delivery process
- Transparent versioning and releases
- Low operational overhead
- A future-proof architecture
Why It Works
This framework aligns Databricks development with the best practices already proven in software engineering. Instead of relying on notebooks as the primary delivery mechanism, the platform becomes the execution engine sitting behind an IaC-driven, testable, automated, high-quality workflow.
In short, this is how you turn Databricks from a notebook playground into a true data engineering platform.